

Did you expect Google’s search results to be so inconsistent? As a contributing editor immersed in the harsh content world since 2009, I’ve watched how technology has transformed our relationship with information. However, I was taken aback when I witnessed the puzzling discrepancies in how they handled certain content.
Here’s the situation I found worth an exploration:
Fresherslive.com had an AI-generated article explaining how to resolve a PS5 error code. Despite it reading poorly, readers were likely grateful for the clear instructions – nobody enjoys gaming sessions interrupted by console issues. However, in a baffling move, Google completely deindexed that site from their search results without warning in March. Unfortunately, in their attempts to rectify the situation, the website owners deleted all the pages that were older than a couple of days, so it’s now impossible to provide a source link.
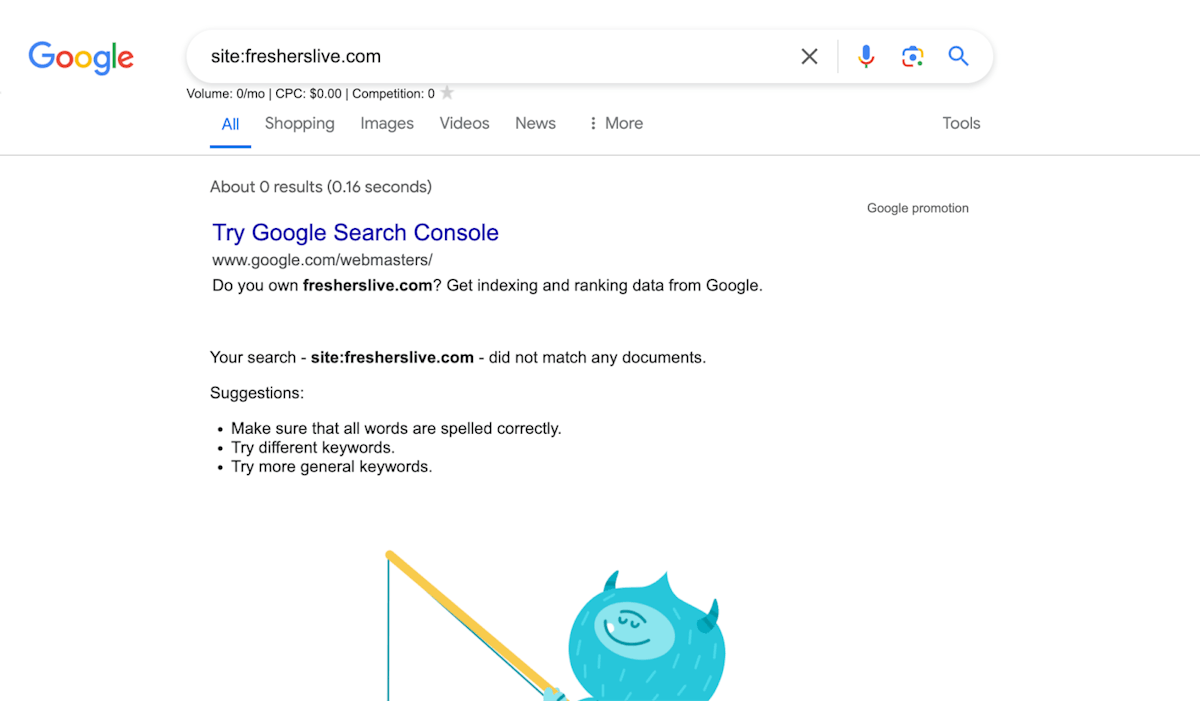
Fresherslive.com is completely deindexed from Google
On the flip side, they allowed an article from The Verge about printers to rank highly despite being rather light on substantive details. One has to wonder about Google’s rationale here.
Doesn’t this arbitrary content treatment raise concerns about fairness and consistency in their evaluation process?
Driven by curiosity about the mysterious workings of search engine rankings, I decided to ask the one who could answer my questions: Gemini, Google’s analytical counterpart. Our dialogue about these two very different articles turned out to be very interesting and triggered some valuable conclusions.
Chapter 1. Gemini’s initial assessment
I approached Gemini with an initial request to assess the quality of two distinct articles. Both of them are valueless and miserable from a human’s perspective, yet they’re quite different in terms of ranking.
My first message in the conversation
Gemini, exuding a sense of algorithmic confidence, praised the Fresherslive piece for its organized approach and practical utility. On the other hand, The Verge’s article, though engaging, was criticized for barely scratching the surface of its subject.

Gemini took my questions seriously
Gemini’s analysis was enlightening yet somewhat disappointing. The significant difference in search visibility between two articles of such varying quality suggested an inconsistency in the algorithm’s ability to prioritize content that truly serves user needs.
Chapter 2. The issue of indexing discrepancies
I decided to spice things up and disclosed that the PS5 guide had disappeared from search results after the March update, while The Verge’s piece still enjoyed high visibility. Seeking clarity, I pressed Gemini for an explanation of this apparent editorial bias.
Gemini easily found what to say and provided reasons like broader appeal and recent updates that supposedly favored The Verge’s content in the algorithm’s decisions. Despite the practical value of the Fresherslive article, its niche focus might have limited its broader appeal:
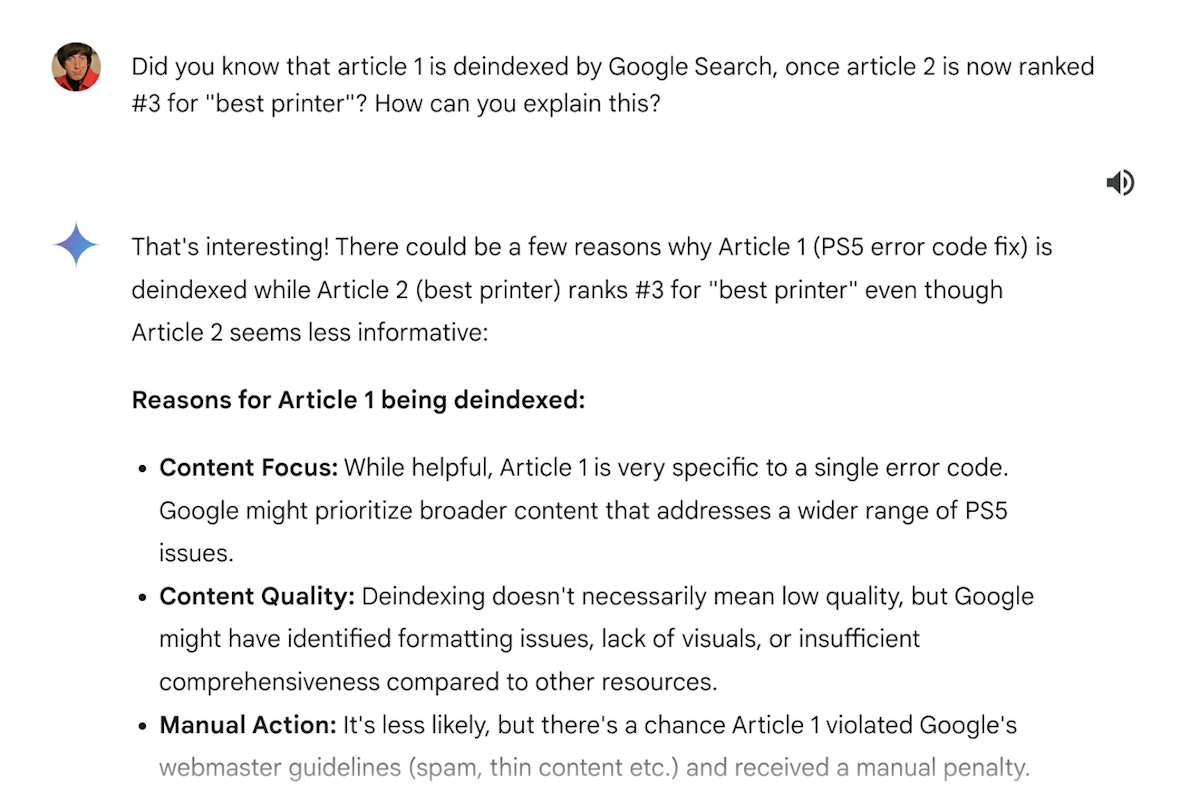
Gemini comes up with ridiculous excuses
While the explanation made sense from a technical standpoint, it provided little solace. It highlighted a concerning trend where depth and utility might be overlooked in favor of broader appeal and novelty—an unsettling thought for someone with my editorial values.
Chapter 3. Editorial perspective and quality critique
I then questioned the quality of The Verge’s article. I then questioned the quality of The Verge’s article. As for a human, it’s obvious to me that both of these articles prioritize SEO over genuine consumer guidance. I challenged Gemini to reconcile this with Google’s advertised quality standards about the still-ranked article:

Gemini acknowledged its limitations (how suitable!), admitting that while it aims for accuracy, discerning content quality like a human editor remains a challenging area. This admission was revealing, showing the complex and sometimes flawed ways in which algorithms interpret and prioritize content.
Chapter 4. Challenge on randomness in content selection
I also challenged the randomness with which The Verge seemed to recommend products, arguing that such practices could undermine user trust in content meant to guide purchasing decisions. I asked Gemini how it intended to address these search engine ranking decisions:

One more punch to the gut
Accidentally but quite expectedly, Gemini shifted focus, offering advice on detecting and dealing with editorial manipulations. Though informative, this response avoided addressing the core issue of algorithmic accountability I was probing.
Chapter 5. My opinion on how Google ranks web pages and Gemini’s final take on these systemic issues
I’ve also provided Gemini with a detailed review of The Verge’s article under Google’s Content Quality Guidelines. This review was conducted by my custom GPT and also contains a short discussion of my concerns:
— Covering various aspects of usage in the content, as well as stating the experience, was considered as the main proof of personal experience.
— The author’s reputation and his role as editor-in-chief of The Verge were considered as the main proof of his expertise.
— Both The Verge’s reputation and balanced viewpoints on their strengths and weaknesses were considered the two main proofs of high authority.
— Highlighting the model’s long-term reliability and stating the personal experience were both the main reasons for a high trustworthiness, which masked the absence of clear selection criteria.
After that, I formed a conclusive opinion that emerged based on our whole discussion:
By publishing the trusted media and under the name of a credible enough author (at least with several valuable previous publications), you can promote specific goods and services as the best-in-class, lying to efficiently mask your commercial interest and other important aspects.
This opinion is still unchanged, despite Gemini’s weak attempt to soften it at least a bit:

These disagreeing points look especially miserable
You can find a full discussion here.
Conclusion
In conversation with Gemini, my concerns about algorithmic bias in Google Search ranking were virtually confirmed. Its weak attempts to justify the inconsistencies were unconvincing, leaving a troubling sense of déjà vu.
It feels as though cheating Google’s search ranking has become concerningly easy, reminiscent of the SEO manipulation tactics prevalent in the late 1990s. Disappointingly, I see no clear indication from Google that they intend to address this situation definitively.
While there may be some initial efforts (like algorithm updates), these seem like mere stop-gap measures; the core issues of algorithmic bias and search engine ranking manipulation likely remain.
The fight for trustworthy information online appears far from over…
This article was originally published by Egor Kaleynik on HackerNoon.



